For our virtual exhibition we conducted this little project of Text Mining on a corpus of Italian newspaper articles written between 2017 and 2020. Our corpus consists of 57 articles extracted from a well-known Italian journal with a Python web-scraper. The articles were tokenized and stopwords were removed before they were saved in .txt format. We extracted word frequencies and plotted them by using Pandas and Matplotlib.
You can find our corpus, the relevant files and the Python scripts at https://github.com/hidden-italy/hidden-italy.github.io/tree/master/news_analysis.
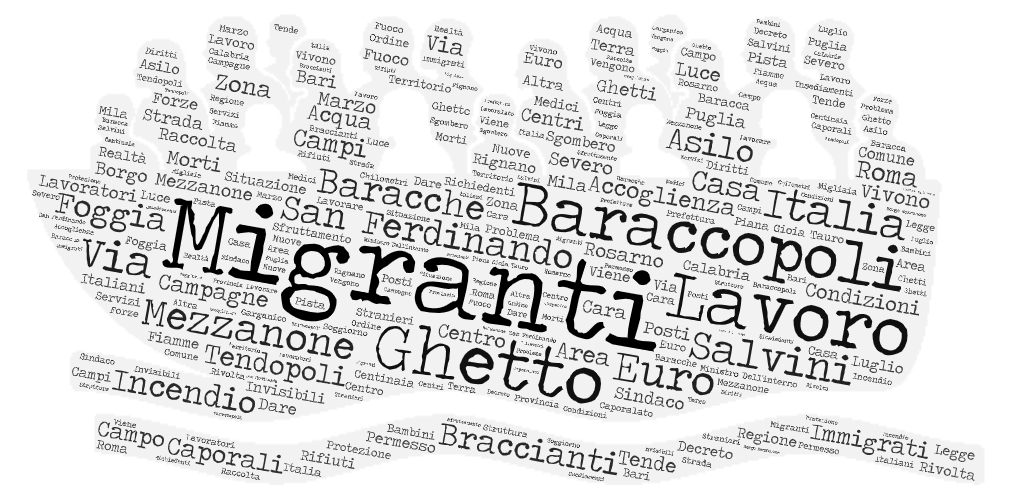
Wordcloud
In this image we plotted the words most frequently used by newspapers to address the issue of migrants in informal facilities between 2017 and 2020. The wordcloud was realized by using the web-based software WordArt.
Relation Extraction
Use the Relation Extraction tool provided by Voyant Tools to see how words are linked together in our collection of newspaper articles.